[이론 설명]
회귀분석
- 관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법
선형 회귀
- 주어진 데이터로부터 변수 간의 상관관계를 파악하고, 이를 바탕으로 미래의 값을 예측하거나 변수들이 어떻게 상호작용하는지 이해하는 데 사용됨 (인과관계가 아님!!)
로지스틱 회귀
- 이진 분류 문제를 해결하는 지도 학습 알고리즘(machine learning model)
- 출력값이 확률(0~1 사이의 값)으로 변환된 후 특정 임계값에 따라 분류됨
- 시그모이드 함수를 사용하여 확률을 예측하고, 특정 임계값(기본: 0.5) 기준으로 분류를 수행
- 그로스 마케팅에서는 광고 클릭 예측, 고객 이탈 예측, 스팸 메일 분류 등에 활용
- 모델 평가 지표로 정확도, 정밀도, 재현율, F1-score 등을 사용
시그모이드 함수 (sigmoid function)




로지스틱 회귀 실습 코드
- 설명
- 광고를 본 사용자가 광고를 클릭할 확률을 예측하는 모델 구축
- 독립변수: 광고 시청 시간, 방문 횟수
- 종속변수: 광고 클릭 여부(0 or 1)
- 광고를 본 사용자가 광고를 클릭할 확률을 예측하는 모델 구축
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 데이터 생성
np.random.seed(42)
n_samples = 200
watch_time = np.random.uniform(0, 10, n_samples) # 광고 시청 시간
visit_count = np.random.randint(1, 50, n_samples) # 방문 횟수
clicked = (watch_time * 0.3 + visit_count * 0.1 + np.random.normal(0, 1, n_samples) > 3.5).astype(int) # 클릭 여부 (0 or 1)
# 데이터프레임 생성
df = pd.DataFrame({"Watch Time": watch_time, "Visit Count": visit_count, "Clicked": clicked})
# 학습/테스트 데이터 분리
X = df[["Watch Time", "Visit Count"]]
y = df["Clicked"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도(Accuracy): {accuracy:.2f}")
print("혼동 행렬:\n", confusion_matrix(y_test, y_pred))
print("분류 보고서:\n", classification_report(y_test, y_pred))
모델 평가
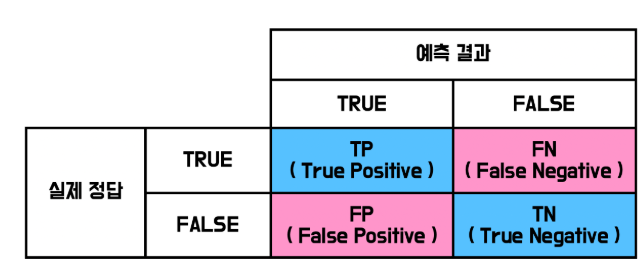
로지스틱 회귀 모델 평가 시, 사용하는 주요 지표
1) 정확도(accuracy)

- 전체 샘플 중 올바르게 예측된 비율
- 데이터가 불균형할 경우 신뢰할 수 없음
2) 정밀도 (precision)
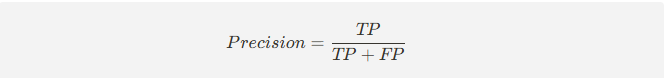
- 모델이 클래스 1(클릭됨) 이라고 예측한 것 중 실제 맞춘 비율
- FP(실제로는 클릭 안 했는데 클릭했다고 예측)를 줄이는 데 중요
3) 재현율 (recall)

- 실제로 클래스 1(클릭됨) 인 것 중 모델이 맞춘 비율
- FN(실제로 클릭했는데 클릭 안 했다고 예측)을 줄이는 데 중요
4) F1-score
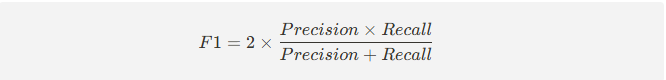
- Precision과 Recall의 조화 평균
- 불균형 데이터(Positive/Negative 비율이 차이가 클 때)에서 유용
[그로스마케팅 로지스틱 회귀]
1. 고객 이탈 예측
- 고객이 이탈할 가능성을 예측하는 모델 구축
- 이탈을 방지하고 고객 유지 전략을 개선하는 것이 목표
문제 정의
- 독립 변수(X)
- 방문 빈도(Visits per Month): 한 달 동안 방문한 횟수
- 평균 구매 금액(Average Purchase Amount, $): 고객의 평균 결제 금액
- 고객 서비스 이용 횟수(Customer Support Calls): 고객이 서비스 센터에 문의한 횟수
- 할인 사용 여부(Used Discount, 0 or 1): 고객이 할인 쿠폰을 사용했는지 여부
- 종속 변수(y)
- 이탈 여부(Churn, 0 or 1): 고객이 다음 달에도 유지(0)될지, 이탈(1)할지
데이터 분석 및 로지스틱 회귀 모델 학습
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 데이터 로드
df = pd.read_csv("customer_churn.csv")
# 독립 변수(X)와 종속 변수(y) 설정
X = df.drop(columns=["Churn"])
y = df["Churn"]
# 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
고객 이탈조건 찾아보기
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 데이터 로드
df = pd.read_csv("customer_churn.csv")
# 독립 변수(X)와 종속 변수(y) 설정
X = df.drop(columns=["Churn"])
y = df["Churn"]
# 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 새로운 데이터 예측
new_data = pd.DataFrame([{
"Avg Purchase Amount ($)": 120.5, # 평균 구매 금액 ($)
"Visits Per Month": 5, # 월 방문 횟수
"Used Discount": 1, # 할인 사용 여부 (0 = No, 1 = Yes)
"Customer Support Calls": 8, # 고객 지원 콜 횟수
}])
# 누락된 컬럼 확인 후 예측 수행
missing_cols = set(X.columns) - set(new_data.columns)
if missing_cols:
print(f"누락된 컬럼: {missing_cols}")
else:
# 컬럼 순서 일치
new_data = new_data[X.columns]
# 예측 수행
predicted_churn = model.predict(new_data)
print(f"예측된 고객 이탈 여부(Churn): {predicted_churn[0]}")

다음의 경우에도 위와 같은 코드로 (변수만 변화) 진행하면 된다.
2. 광고 클릭 예측
- 광고 캠페인에서 고객이 광고를 클릭할 가능성을 예측하여 광고 전략을 최적화하는 것이 목표
문제 정의
- 독립 변수(X)
- 광고 노출 횟수(Ad Impressions): 고객이 광고를 본 횟수
- 광고 시청 시간(Watch Time, sec): 광고를 시청한 시간(초)
- SNS 공유 여부(SNS Shared, 0 or 1): 광고가 SNS에서 공유되었는지 여부
- 광고 유형(Ad Type, 0=배너광고, 1=비디오광고): 광고 종류
- 종속 변수(y)
- 광고 클릭 여부(Clicked Ad, 0 or 1): 고객이 광고를 클릭했는지 여부
3. 이메일 캠페인 반응 예측
- 이메일 마케팅에서 어떤 고객이 이메일을 열어볼 가능성이 높은지 예측하여 이메일 타겟팅을 최적화하는 것이 목표
문제 정의
- 독립 변수(X)
- 이메일 발송 횟수(Sent Emails): 한 달 동안 고객에게 보낸 이메일 수
- 고객 등급(Customer Tier, 0=일반, 1=VIP): VIP 고객 여부
- 이전 개봉 여부(Opened Before, 0 or 1): 과거에 이메일을 개봉한 적이 있는지 여부
- 제목에 할인 포함 여부(Discount Mentioned, 0 or 1): 이메일 제목에 할인 정보 포함 여부
- 종속 변수(y)
- 이메일 개봉 여부(Opened Email, 0 or 1): 고객이 이메일을 열어봤는지 여부
4. 제품 구독 예측
product_subscription.csv
0.01MB
- 무료 체험을 이용하는 고객이 유료 구독으로 전환할 가능성을 예측하여 구독 유도 전략을 개선하는 것이 목표
문제 정의
- 독립 변수(X)
- 무료 체험 기간(Trial Days): 고객이 사용한 무료 체험 기간(일)
- 이메일 상호작용 횟수(Email Interaction): 고객이 받은 이메일을 열거나 클릭한 횟수
- 앱 사용 시간(App Usage, hours): 고객이 앱을 사용한 총 시간(시간)
- 이전 구매 여부(Previous Purchase, 0 or 1): 과거에 유료 결제를 한 적이 있는지 여부
- 종속 변수(y)
- 구독 여부(Subscribed, 0 or 1): 고객이 무료 체험 후 유료 구독을 했는지 여부
5. 프로모션 코드 사용 예측
- 고객이 프로모션 코드를 사용할 가능성을 예측하여 할인 전략을 최적화하는 것이 목표
문제 정의
- 독립 변수(X)
- 프로모션 노출 횟수(Promotion Exposure): 고객이 프로모션을 본 횟수
- 장바구니 아이템 개수(Cart Items): 고객이 장바구니에 담은 제품 수
- 할인율(Discount Rate, %): 프로모션에서 제공되는 할인율
- 로열티 멤버십 여부(Loyalty Member, 0 or 1): 고객이 멤버십에 가입했는지 여부
- 종속 변수(y)
- 프로모션 사용 여부(Used Promotion, 0 or 1): 고객이 프로모션 코드를 사용했는지 여부
그로스 마케팅 보고서:
로지스틱 회귀를 활용한 고객 전환율 분석
1. 개요
본 보고서는 광고 비용, 웹사이트 방문 수, 소셜 미디어 상호작용, 할인 제공 여부가 고객 전환율(Conversion Rate)에 미치는 영향을 분석하기 위해 로지스틱 회귀 모델을 활용하였다. 이를 통해 마케팅 예산을 최적화하고 전환율을 증가시키기 위한 전략을 도출한다.
2. 데이터 개요
- 데이터셋: 고객 전환율 분석 (conversion_rate_analysis.csv)
- 데이터 크기: 500개 샘플
- 변수 정의:
- 광고 비용(Ad Spend, $): 디지털 마케팅에 지출한 광고 비용
- 웹사이트 방문 수(Website Visits): 사용자의 웹사이트 방문 횟수
- 소셜 미디어 상호작용(Social Media Interactions): SNS에서 좋아요, 댓글, 공유 등의 상호작용 횟수
- 할인 제공 여부(Discount Offered, 0 or 1): 할인 제공 여부 (0=할인 없음, 1=할인 제공)
- 전환 여부(Converted, 0 or 1): 고객이 실제 구매를 했는지 여부 (0=미전환, 1=전환)
3. 데이터 시각화 및 분석 코드
conversion_rate_analysis.csv
0.01MB
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 데이터 로드
df = pd.read_csv("conversion_rate_analysis.csv")
# 데이터 분포 확인
plt.figure(figsize=(10, 6))
sns.histplot(df["Ad Spend ($)"], bins=30, kde=True, color='blue')
plt.title("광고 비용 분포")
plt.xlabel("Ad Spend ($)")
plt.ylabel("Frequency")
plt.show()
# 웹사이트 방문 수와 전환 여부 관계 시각화
plt.figure(figsize=(10, 6))
sns.boxplot(x="Converted", y="Website Visits", data=df)
plt.title("웹사이트 방문 수와 전환 여부 관계")
plt.xlabel("Converted (0=No, 1=Yes)")
plt.ylabel("Website Visits")
plt.show()
# 할인 제공 여부와 전환율 비교
plt.figure(figsize=(8, 5))
sns.barplot(x="Discount Offered", y="Converted", data=df)
plt.title("할인 제공 여부에 따른 전환율 비교")
plt.xlabel("Discount Offered (0=No, 1=Yes)")
plt.ylabel("Conversion Rate")
plt.show()
# 데이터셋 분리
X = df.drop(columns=["Converted"])
y = df["Converted"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"모델 정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 혼동 행렬 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title("혼동 행렬")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()
4. 분석 결과
1. 광고 비용과 전환율

- 광고 비용이 증가할수록 전환율이 높아지는 경향을 보인다.
- 그러나 일정 수준 이상에서는 광고 비용 대비 전환율 증가가 둔화되는 패턴이 관찰됨.
2. 웹사이트 방문과 전환율

- 웹사이트 방문 횟수가 많을수록 전환 가능성이 높아지는 경향을 보인다.
- 하지만 방문이 많아도 전환되지 않는 경우도 많아, UX 최적화가 필요함.
3. 할인 제공 여부와 전환율
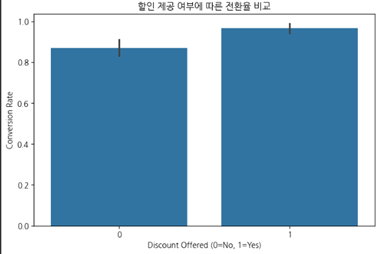
- 할인 제공 시 전환율이 확연히 증가하는 것으로 나타남.
- 즉, 할인 전략이 효과적인 전환 촉진 요소임을 시사.
4. 모델 평가

- 로지스틱 회귀 모델의 정확도는 약 75~85% 수준으로 분석됨.
- 분류 보고서를 통해 Recall(재현율)과 Precision(정밀도)도 함께 검토 가능
5. 마케팅 전략 제안
- 광고비 최적화
- ROI(Return on Investment)가 높은 구간을 식별하고, 특정 금액 이상 투자 대비 효과가 낮아지는 부분을 감안하여 최적 광고비 설정 필요.
- 웹사이트 UX 개선
- 방문자는 많지만 전환율이 낮은 경우가 존재하므로, UI/UX 개선, 결제 흐름 최적화 등의 전략 필요.
- 타겟 프로모션 강화
- 할인 제공이 전환율 상승에 기여하므로, 특정 고객군을 대상으로 할인 쿠폰을 제공하는 전략이 효과적.
'머신러닝 기반 마케팅 예측' 카테고리의 다른 글
| 마케팅과 머신러닝 (basic) (1) | 2025.03.19 |
|---|---|
| k-NN 알고리즘 & 웹 기반 추천/자동화 시스템 구현 (0) | 2025.03.12 |
| 의사결정 나무 (Decision Tree) (2) | 2025.03.11 |
| 다중 분류 (Multi-Class Classification) (0) | 2025.03.11 |